
US-based CEVA today announced “the world’s most powerful DSP architecture” in its Gen4 CEVA-XC. The new architecture handles complex parallel processing workloads required for 5G endpoints and Radio Access Networks (RAN), enterprise access points and other multigigabit low-latency applications.
“5G is a technology with multiple growth vectors spanning consumer, industrial, telecom and AI. Addressing these fragmented and complex use cases requires new thinking and practices for processors. Our Gen 4 CEVA-XC architecture encapsulates this new approach, enabling never-before-seen DSP core performance through groundbreaking innovations and design,” said Aviv Malinovitch, Vice President and General Manager of the Mobile Broadband Business Unit at CEVA.
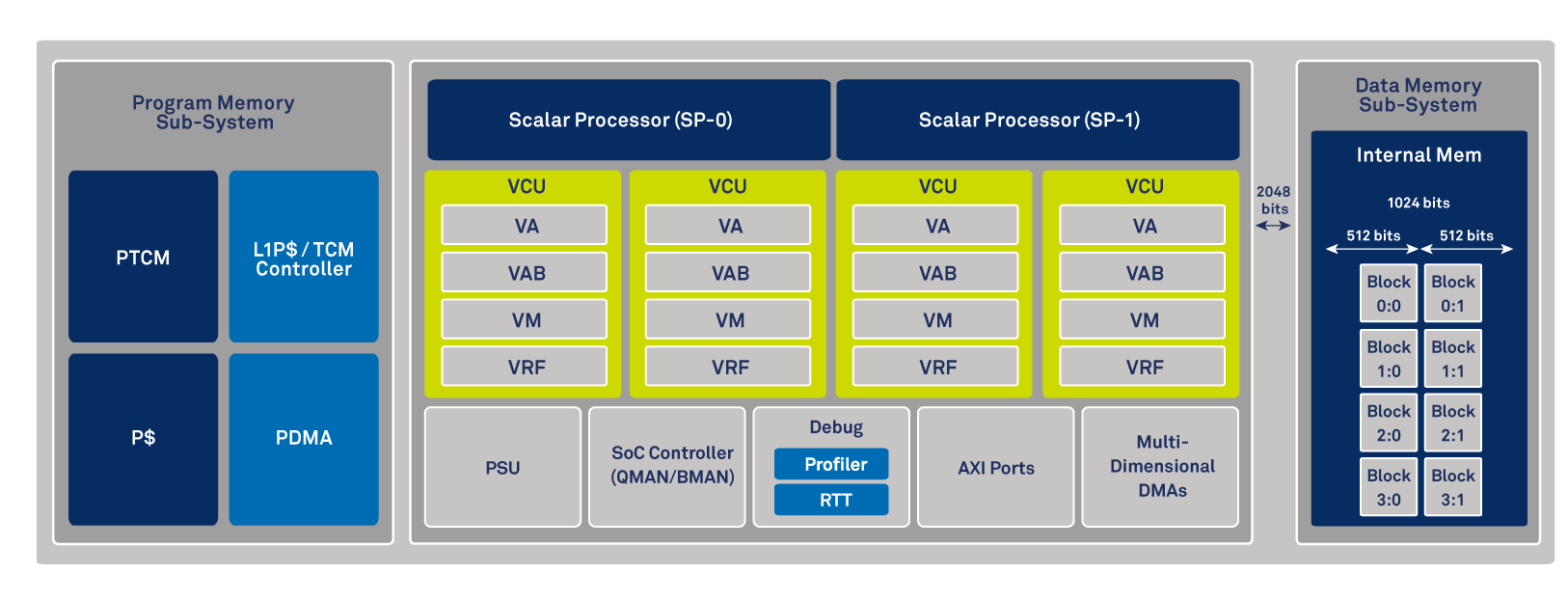
The Gen4 CEVA-XC combines scalar and vector processing, enabling two-times 8-way VLIW and up to 14,000 bits of data level parallelism. It incorporates an advanced, deep pipeline architecture enabling operating speeds of 1.8GHz at a 7nm process node, using a unique physical design architecture for an innovative multithreading design. The processors can be dynamically reconfigured as either a wide SIMD machine or divided into smaller simultaneous SIMD threads.
Gen4 CEVA-XC also features a new memory subsystem, using 2048-bit memory bandwidth, with coherent, tightly-coupled memory to support efficient simultaneous multithreading and memory access.
Multicore CEVA-XC16 is the first processor in the Gen4 CEVA-XC architecture series, which the company claims to be “the fastest DSP ever made”.
The CEVA-XC16 offers high parallelism of up to 1,600 Giga Operations Per Second (GOPS) that can be reconfigured as two separate parallel threads. These can run simultaneously, sharing their L1 Data memory with cache coherency, which directly improves latency and performance efficiency for PHY control processing, without the need for an additional CPU. These new concepts boost the performance per square millimeter by 50% compared to a single-core/single-thread architecture when massive numbers of users are connected in a crowded area. This amounts to 35% die area savings for a large cluster of cores, as is typical for custom 5G base station silicon.






