
By Mark Patrick, Technical Marketing Manager, EMEA, Mouser Electronics
Training and running a neural network on a powerful desktop computer is relatively straightforward; but what if the application should run on a battery-powered handheld device, or if there’s an unreliable or non-existent wireless connectivity?
We have all become accustomed to our smartphone answering questions. They do so via wireless connectivity to send a captured audio file to an AI cloud service, where a neural network trained to detect words searches for a result and initiates actions. The neural networks used are artificial interpretations of how the brain works – but must be trained to learn.
There are different type neural networks, each suited to specific tasks. The most popular neural networks are recurrent (RNN) and convolutional (CNN). RNNs are suited to voice recognition tasks such as those used by Alexa, Siri and Google Voice, whereas CNNs are most suited to image classification and recognition applications.
Training a neural network is a computationally-intensive process, typically performed on high-performance workstations, servers or highly-scaleable cloud computing resources. Using a trained neural network, the deployment – more commonly known as “inference phase”, tends to be less resource-demanding. However, there is still the need for a reasonable amount of computing resources and, in the smartphone, this is provided by hugely-scaleable cloud services. With this process, apart from sending the audio stream to the cloud, the energy demand on the device’s already heavily-optimised battery is insignificant.
Edge constraints
Examples such as these are only made possible through reliable wireless connection, offloading the computing tasks to the cloud and the smart device having a decent-sized battery. Also, in many of our interactions with digital assistants, we can’t tell of any delay or latency of the task being actioned. Without the wireless link to the cloud, inference would not occur. But moving the inference task to the local device demands a higher-performance processor in the device, which in turn pushes up its power consumption. As AI-based applications become more pervasive, particularly those in areas with unreliable wireless infrastructure, these constraints are limiting product innovations. For example, a handheld device can be used for detecting diseases in remote regions, but the wireless infrastructure needs to be in place or have the right batteries in the devices for seamless support.
Inference at the edge
Provisioning inference at the edge is seen as a game changer and, in common with many technology trends, it is attracting significant investment. Some start-ups are in the process of designing high-performance, low-power inference engines – heavily-optimised sets of dedicated processors with large amounts of high-bandwidth memory.
Take the ACI-accelerating company Mythic as an example. Its IPU features an array of tiles, each tile with a large analogue compute array to store bulky neural network weights, local SRAM memory for data being passed between the neural network nodes, a single-instruction multiple-data (SIMD) unit for processing operations not handled by the analogue compute array, and a nano-processor for controlling the sequencing and operation of the tile. The tiles are interconnected with an efficient on-chip router network, which facilitates the data flow from one tile to the next. On the edge of the IPU, there’re off-chip connections to either other Mythic chips or the host system, speeding the inference process.
In addition to the flurry of inference engine innovations, some of the existing processor vendors have taken an alternative approach to providing AI at the edge.
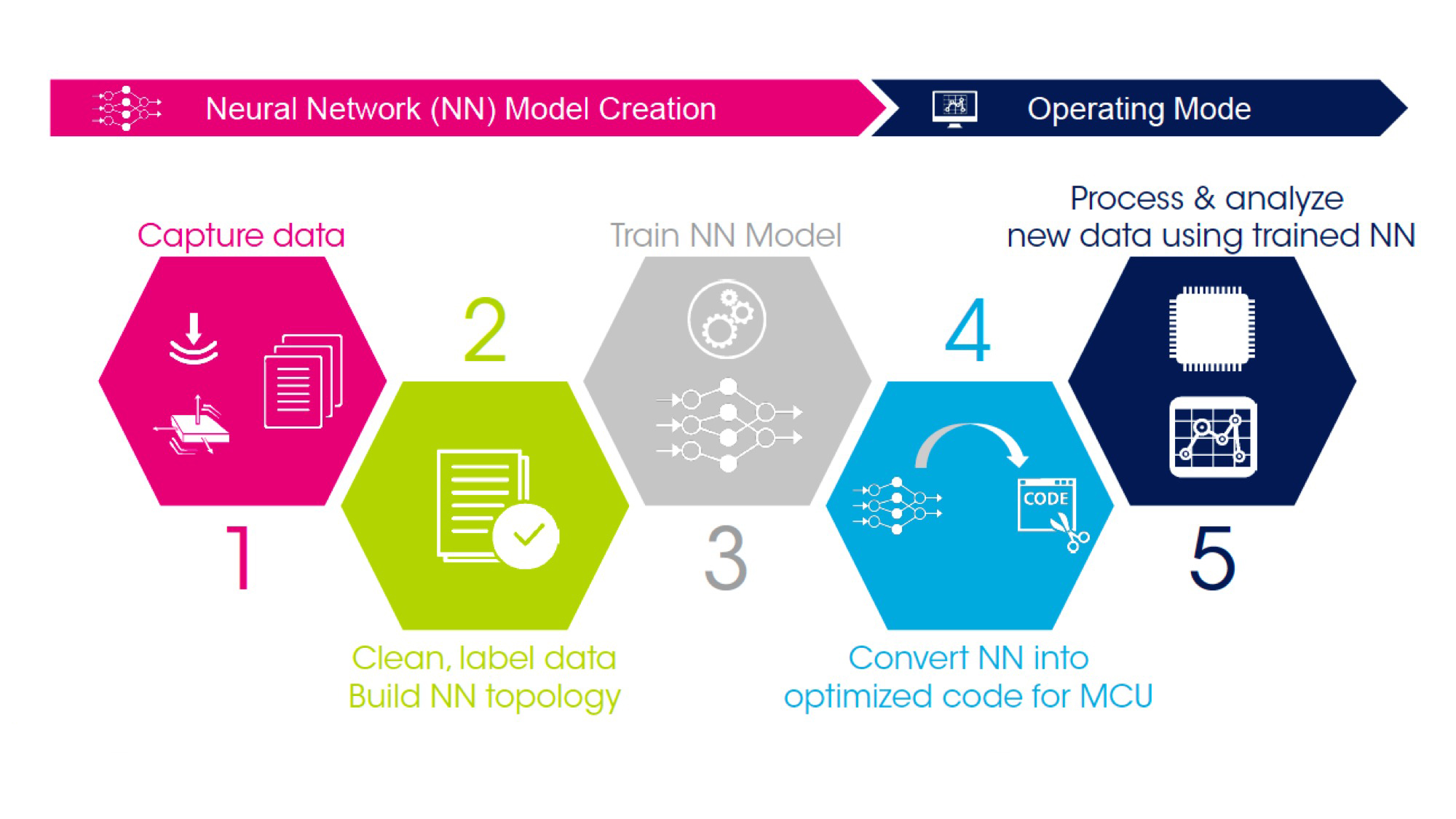
Optimising neural networks for MCUs
STMicroelectronics’s microcontrollers can be used for ‘inference at the edge’ applications. Rather than attempt to re-architect a microcontroller for inference, STMicroelectronics’s approach is to use its existing high-performance, low-power STM32 series of microcontrollers, trained neural network code optimised for embedded applications, and the STM32 Cube.AI toolchain; see Figure 1. Using existing microcontrollers, together with a comprehensive toolchain support and ecosystem of development boards, libraries and partners, greatly simplifies the task of developing an edge-based AI solution. The network model still needs training for the specific application, but this can be achieved in the traditional manner. In addition to converting the neural network algorithm into MCU code, the STM32 Cube.AI toolkit includes audio and motion application examples. A range of sensor modules that can be used to capture data during model training are also available for the STM32 series.
Limitless opportunities
The ability to deploy neural networks within portable, battery-powered devices will create a host of new applications. Removing the dependency of always-on connectivity will also bring AI-enabled services to remote and hostile locations, which, for a start, will be of crucial importance to aid agencies and disaster response teams.






