

The shift from cloud to edge computing has changed the sensor node concept, from using a simple DSP near the sensor, to applying deep neural networks functionality at the sensor level. Hence, most recent trends in this field have targeted device energy optimisation and computing latency reduction.
Going parallel
Traditional computers process tasks sequentially: once a task is completed, the next one begins. Although this method still serves many applications today, demands are calling for faster, more-optimised and more energy-efficient computations, where parallel processing fits the bill.
Computer scientists and engineers approached parallel processing like the human brain, where data is distributed in parallel to all neurons of a layer, then instantly propagated to another layer, giving rise to neuromorphic computing. This makes neural networks computationally fast, allowing analysis and decisions to be as close to real time as possible. It also makes them much more energy-efficient than other type processing, but, crucially, more robust, too. For example, an error in an algorithm code will most inevitably lead to a system error, whereas if an error appears in one or several connections in a neural network, this does not lead to failure – all connections are interdependent, work in parallel, and are duplicated on multiple levels.
Neural network implementations
A digital neural network is a model with simulated neurons, using standard step-by-step consecutive math operations in the digital processor core. Digital implementation is not well suited to neural network processing, since it cannot process massively parallel data, necessary for neural network computation. Digital neural networks can be implemented on traditional processors, but with lower efficiencies.
There has been significant progress in neural network digital implementation over the past 20 years. It has mainly focused on parallel processing developments resulting in a certain level of parallelism of Graphics Processing Unit (GPU) and Tensor Processing Unit (TPU) – AI accelerator ASIC – solutions. However, the energy consumption problem was not resolved, especially since there is an intensive exchange with memory within these units. Increasing the number of processing units also adds to the power budget.
In comparison, billions of years of evolutionary development has led to the human brain with its 80 billion neurons to consume only 20W, leading to the development of analogue neuromorphic design for efficient neural network implementation.
Neuromorphic analogue computing mimics the brain’s function and efficiency by building artificial neural systems that implement “neurons” and “synapses”, to transfer electrical signals in analogue circuit design. Analogue neuromorphic ICs are intrinsically parallel and better adapted for neural network operations.
An analogue neuromorphic model of a single neuron with a fixed resistor as weights representation is better than a digital model, because N multibit MAC operations in analogue essentially require N+1 resistors, while in digital, they normally require N*(10~40) transistors per bit, or N*(80~320) transistors for 8-bit precision. Therefore, the analogue neuromorphic model is fundamentally superior in terms of single-neuron performance. Any current disadvantages of analogue circuits are not fundamental, and are only related to some engineering challenges.
The most important advantage of digital solutions is the possibility of reusing a single computational block (i.e., an ALU or a hardware multiplier) many times whilst feeding it new weights and data. However, this approach creates a memory-related power bottleneck, since data transfer becomes more energy-consuming than the computations themselves.
Current efforts are being undertaken to make analogue neural network processors mostly use the in-memory computing approach.
The in-memory approach
In-memory computing addresses the memory problem, but because it puts all the weights on a chip in crossbars, it suffers from a large chip size.
Another problem of in-memory computing is poor area utilisation. On one hand, the memory array can’t be too small (memory cells overhead dominating the area is not efficient); on the other, the memory crossbar is an all-to-all connection, but the possible number of inputs for each neuron is limited by noise. So, if the array is too big, most memory cells are useless, which creates a significant area overhead.
In practice, memory utilisation is not more than 40-50%, even in cases when the network is optimised for the hardware, and such hardware optimisation significantly constrains the network architecture. Typical arrays are limited to 256-512 cells in width and height, whereas reasonably small networks may easily have 2,000-4,000 neurons in a single layer.
Another limitation of in-memory computing is limited precision, a measure of quality. The SRAM is 1 bit per cell; existing Flash memory is up to 4-5 bits per cell.
Other types of in-memory options (MRAM, PCM, ReRAM, FeRAM) rate low in TRL (technology readiness level) and don’t promise multibit production-level solutions in the next few years.
AI
Karl Friston, a leading scientist in the area of neurophysiology and AI, created the Free Energy Theory, which proposes that brain connections minimise entropy by means of making representations that predict sensory signals. The model of the environment is built on the basis of sensory information and its interpretation. More information input results in a more complex model of the environment. The Friston concept does not limit itself to brain operation and is valid for any AI system.
According to neurobiological research, the retina, visual nerve and some areas of the neocortex are fixed at a very early age of a person’s development, and do not change their entire life. The same is true for the hearing system (see Figure 1), which includes both the ears and the auditory parts of the sensory system. The active state (always-on) located in our ear detects and extracts sounds, which the brain interprets.

Figure 1: The human perception of voice according to Karl Friston’s Free Energy Theory
Figure 1 shows the human perception of voice according to Karl Friston’s theory: there are “blanket states” of the peripheral cortex (the human retina and ear), reflecting direct perception of information, which are always on, and transfer information to the brain hemispheres for classification. Since these blanket states do not change, they have a “fixed neuron connection structure”. The output coming from those blanket states in AI terminology is called “embeddings” – they are representations containing densely-packed information about sensory input formed by a neural network or biological nervous system. Embeddings are formed in hidden layers of a neural network and contain the most significant information about input data. Embeddings are used as input data for further efficient processing, classification and interpretation.
Neuromorphic analogue signal processing
Neuromorphic analogue signal processing technology, or NASP, perceives raw data signals to add “intelligence” to various sensors. The architecture contains artificial neurons – nodes performing computations, implemented with operational amplifiers, and axons – the connections with weights between the nodes, implemented in thin-film resistors.
The NASP chip design embodies the approach of a sparse neural network, with only the necessary connections between neurons required for inference. In contrast to in-memory designs, where each neuron is connected to each neighboring neuron, the NASP approach simplifies chip layout. This design especially suits Convolutional Neural Networks (CNN), where connections are very sparse, as well as Recurrent Neural Networks (RNN), transformers and autoencoders.
The NASP T-Compiler converts the already trained and optimised neural network math model into the chip structure, offering area utilisation close to 100% (and it can be exactly 100% in practice), and 8 bits per weight with current technology. This approach yields a faster time to market, lower technical risks and better performance. Furthermore, NASP proposes a hybrid core approach, similar to that described in the latest neuroscientific works on human brain data processing.
NASP technology combines the fixed weights method, which implies complete separation of inference and training, with a fixed chip structure, similar to the human visual nerve and retina, and a flexible part (which can differ depending on application), responsible for further classification of the received embeddings.
There is a well-known phenomenon of Machine Learning: after several hundred training cycles (also known as epochs), the deep convolutional neural network maintains fixed weights and the structure of the first 80-90% of the layers, and in the following cycles, only the few last layers responsible for classification continue to change weights – a property also used in Transfer Learning. This fact is the key to a hybrid concept, where a chip with fixed neural networks is responsible for pattern detection, combined with a flexible algorithm – which could be any type, including an additional flexible neural network – responsible for the pattern interpretation.
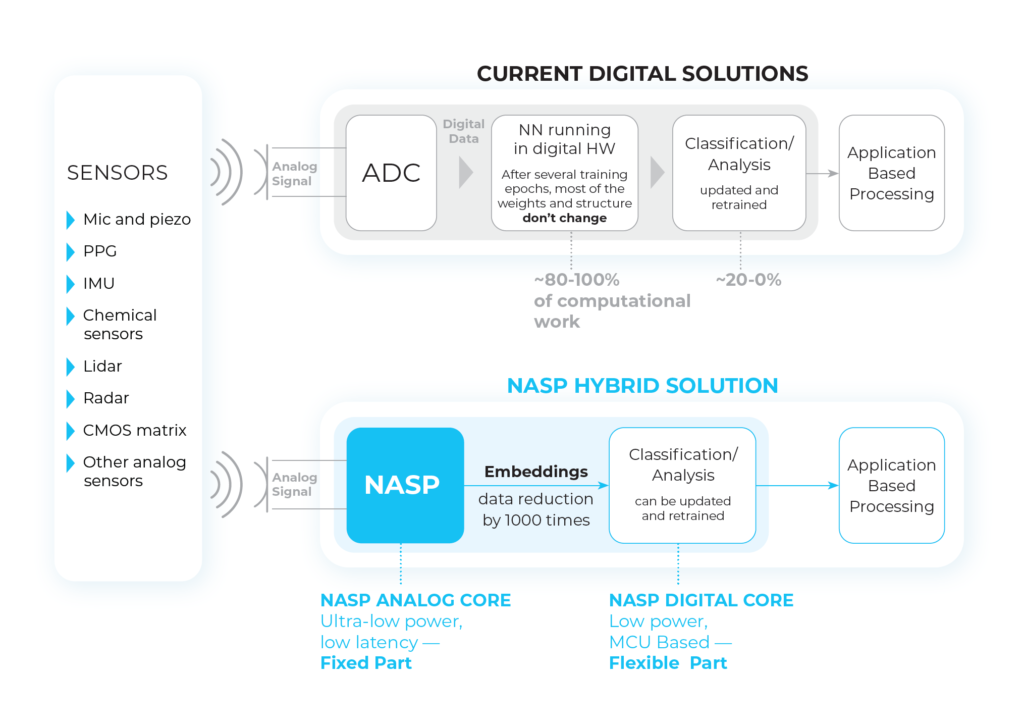
See Figure 2 for a neural network implementation with Transfer Learning technique in a digital standard node vs the NASP hybrid solution that uses an analogue circuit.
The neural network (NN) running on digital processors (CPU, GPU, and TPU) allocates resources in the following way: 1. Raw data pre-processing consumes about 80% of the computational resources 2. Classification and decision making consume much fewer resources. The NASP solution uses the principle of Transfer Learning where the most layers of a neural network responsible for raw data preprocessing remain unchanged after a certain number of training epochs (Fixed Analogue Core), and only last few layers are updated while receiving new data and retraining it (Flexible Digital Core).
Another important element of the NASP solution is effective pruning to minimise the trained network, which is to be converted into chip production files. Since the neural core runs with weights, fixed after training of the neural network, we can effectively prune the initial neural network before converting it into an internal math model in a digital format. Pruning can reduce the neural network 2 to 50 times, depending on its structure. And since the final chip is built according to the prepared architecture and structure, pruning drastically reduces the final chip size and power consumption.
NASP performance
Table 1 shows a comparison of energy per inference metric of a NASP chip vs some digital solutions:
| NASP | Raspberry Pi3 B+ | Snapdragon-710 | Jetson TX1 | |
| MobileNet V.2 [joule/inference] | 2,5 x10-3 | 3,25 | 0,72 | 0,2 |
Table 1: Comparison of energy per inference metric of a NASP chip vs some digital solution
Raspberry PI3 B+ has one processor, Snapdragon has a processor with a GPU accelerator, and Nvidia Jetson has a 256-core GPU. For NASP, we have used a chip simulation (D-MVP) model and data from the NASP test chip.
The comparison demonstrates NASP’s greater energy efficiency, due to the analogue neuromorphic nature of the IC. Also, it is important that the NASP chip size completely fits the requirements of the neural network (Mobile Net V2), leaving no overhead at all. This is especially important for small neural networks, where the NASP efficiency advantage becomes much greater.
Examples of NASP use
The embedding extraction and processing approach in human activity recognition is based on 3-axis accelerometer signals. A trained autoencoder neural network encodes various types of human activities, and then decodes them without losing accuracy.
After generating such an array of patterns (embeddings), a neural network will recognise the human activities encoded in the patterns. The system consists of an encoder function, implemented in fixed neurons in an analogue processor (NASP), and the classifier, implemented in a digital processor. The fixed analogue part of the NASP chip takes approximately 90% of the whole workload, and the activity recognition interpretation takes around 10%, resulting in a low load on the digital subsystem.
An important feature of using such embeddings generated by the encoder neural network is that, if a human practiced some new physical activity (which was not trained previously during the neural network training stage), the unique descriptor would be formed anyway, differentiating this activity from other classes of embeddings. Thus, it would be a totally new compact size pattern, dedicated to that activity. In other words, it is still possible to introduce new classes not included in the fixed trained network, significantly broadening the application of NASP-based products.
Taking this to the industrial setting: predictive maintenance helps optimise processes by collecting and analysing a huge data flow generated by vibrational sensors that measure machinery, tracks, railway cars, wind turbines and oil and gas pumps. This data flow shortens the battery life of operating sensor nodes. A NASP solution reduces the data flow from vibration sensors by 1000 times, using the same encoder-decoder approach, and transmitting through LoRa (or other low-power technology) only embeddings extracted from the initial data. It is worth noting that the autoencoder systems and embedding will create new classes, describing new signals of vibration sensors, even if they were not trained to recognise these types of signal patterns. Thus, by applying an encoder neural network, in this case, rigidly built in NASP, a whole range of different signals from various vibration sensors can be obtained for analysis by a digital system, which will identify any machine malfunctions. The use of the embeddings reduces data sent to the cloud, solving the fundamental problem of low bandwidth required by IoT systems.
By Alexander Timofeev, CEO and Founder, Polyn Technology






