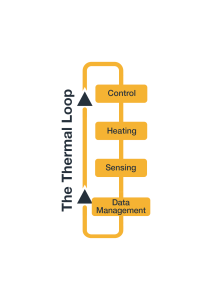
DigiKey and LabsLand release Prism4 remote engineering hardware system 19th April 2024 DigiKey now offers exclusively the LabsLand Prism4 release, a modular structure for building interactive real-time, remote hardware systems faster and more efficiently. The Prism4’s design
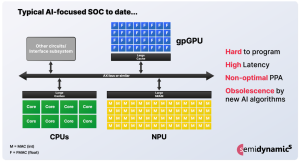
News Partners join forces on energy-efficient, security-enhanced SoC with PUF-based Root of Trust 9th April 2024
Products New isolated DC-to-DC converters for consumer, industrial and IoT applications 18th April 2024
Products New isolated DC-to-DC converters for consumer, industrial and IoT applications 18th April 2024
News Syntiant unveils NDP250 neural decision processor with next-gen core 3 architecture 11th April 2024
Applications Isolated digital input chips offer simplified, flexible configuration in industrial applications 7th February 2024
News UK’s first master’s degree in applying AI tools to engineering and design is now open at the University of Bath 28th February 2024
Events Free educational seminars taking place at Electronics Live on 17th January at the NCC in Birmingham 5th January 2024
News Partners join forces on energy-efficient, security-enhanced SoC with PUF-based Root of Trust 9th April 2024
Products New isolated DC-to-DC converters for consumer, industrial and IoT applications 18th April 2024
News Siemens joins Semiconductor Education Alliance to address skills and talent shortage in global semiconductor industry 7th March 2024